
I am an Assistant Professor of Aerospace Engineering at Rensselaer Polytechnic
Institute, where I lead the Computational Scientific Machine Learning (CSML) Lab. I work on the
frontiers of AI for physical systems by developing transformative numerical and data-driven methods for
predictive modeling, inverse problems, and control of complex large-scale dynamical systems, ultimately
accelerating scientific discovery across engineering and applied sciences.
I earned my Ph.D. in Aerospace Engineering and Scientific Computing from the University of Michigan (2021), and completed postdoctoral research at the
AI Institute in Dynamic Systems at the University of Washington. I am
affiliated with the Rensselaer-IBM AI Research Collaboration. Our lab has
access to numerous high-end HPC clusters (A100/A6000/GB200).
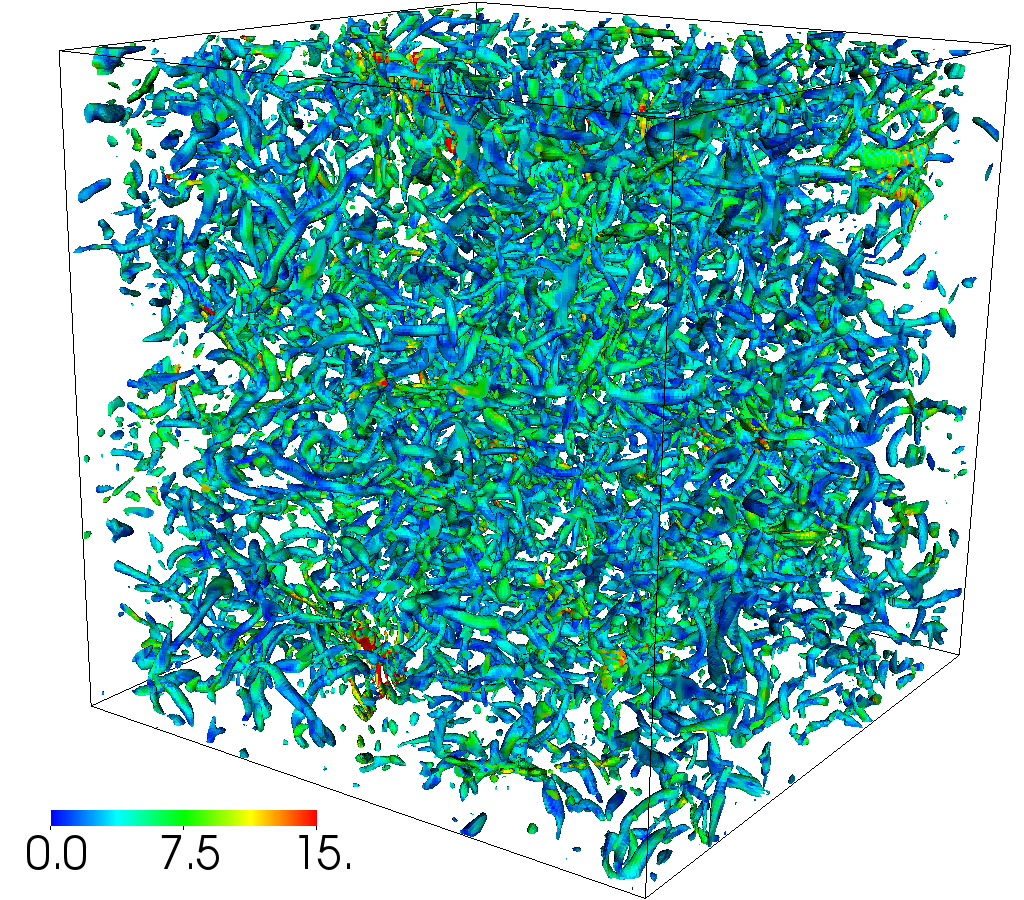
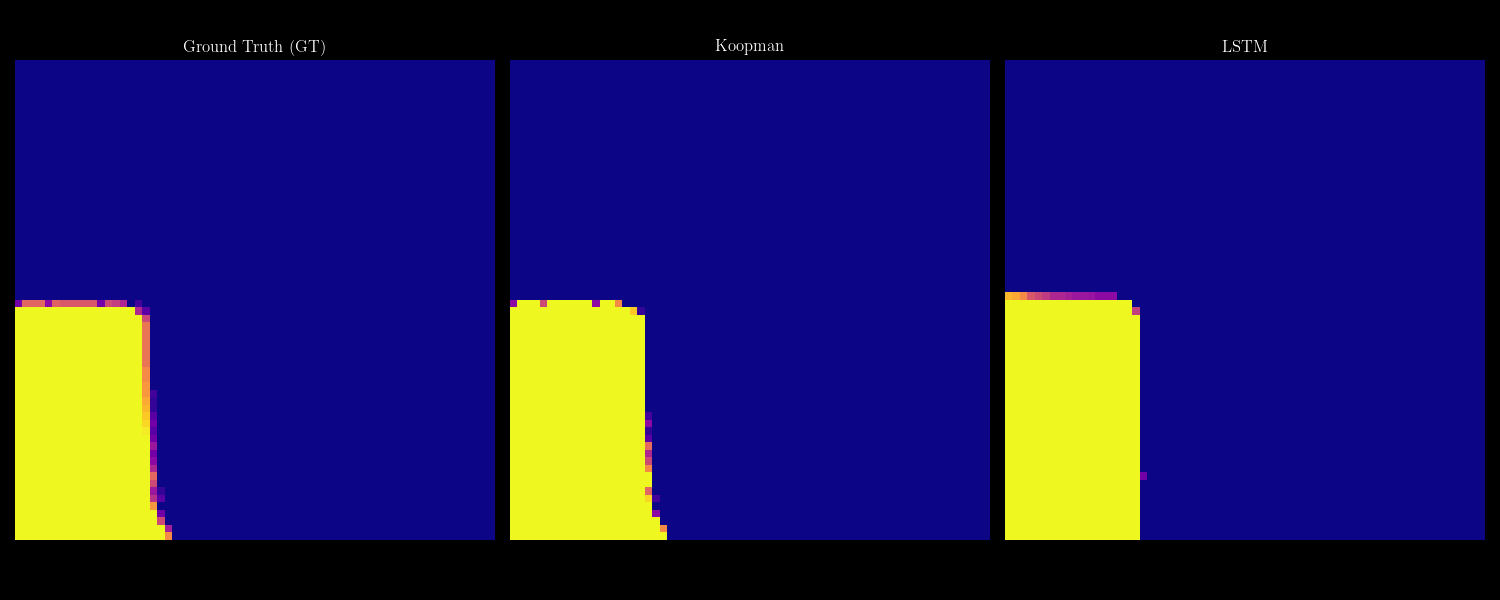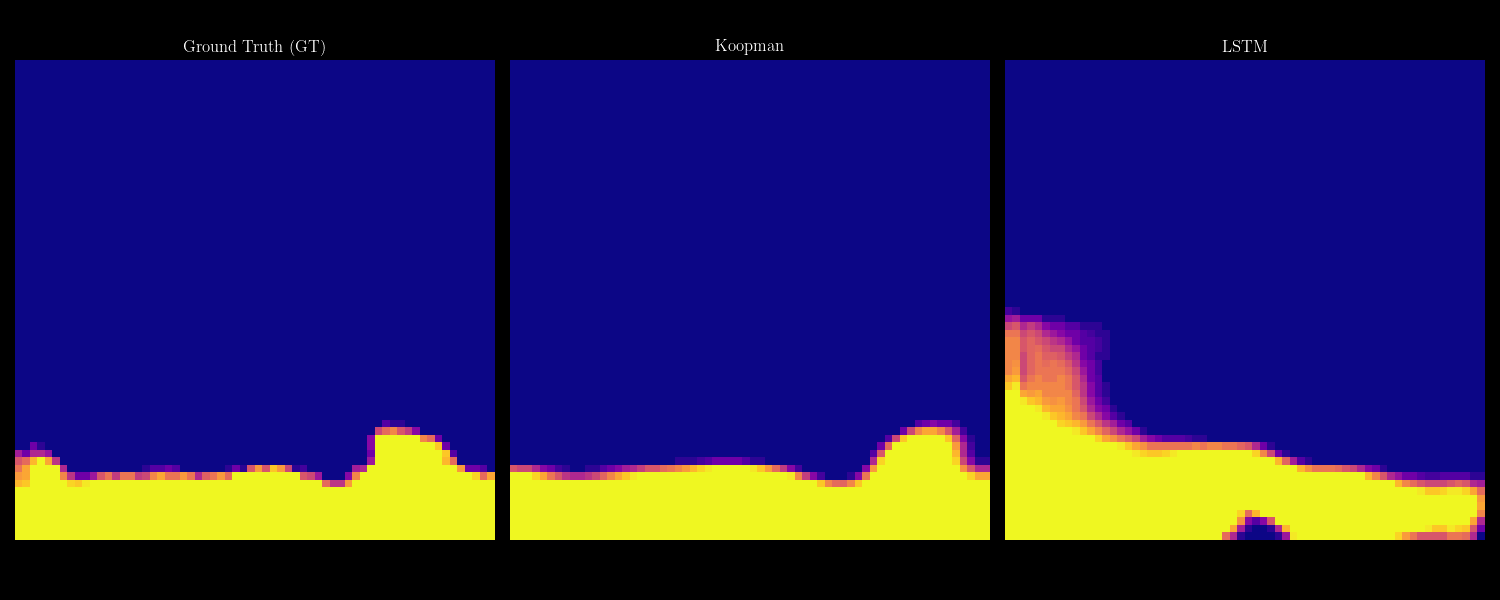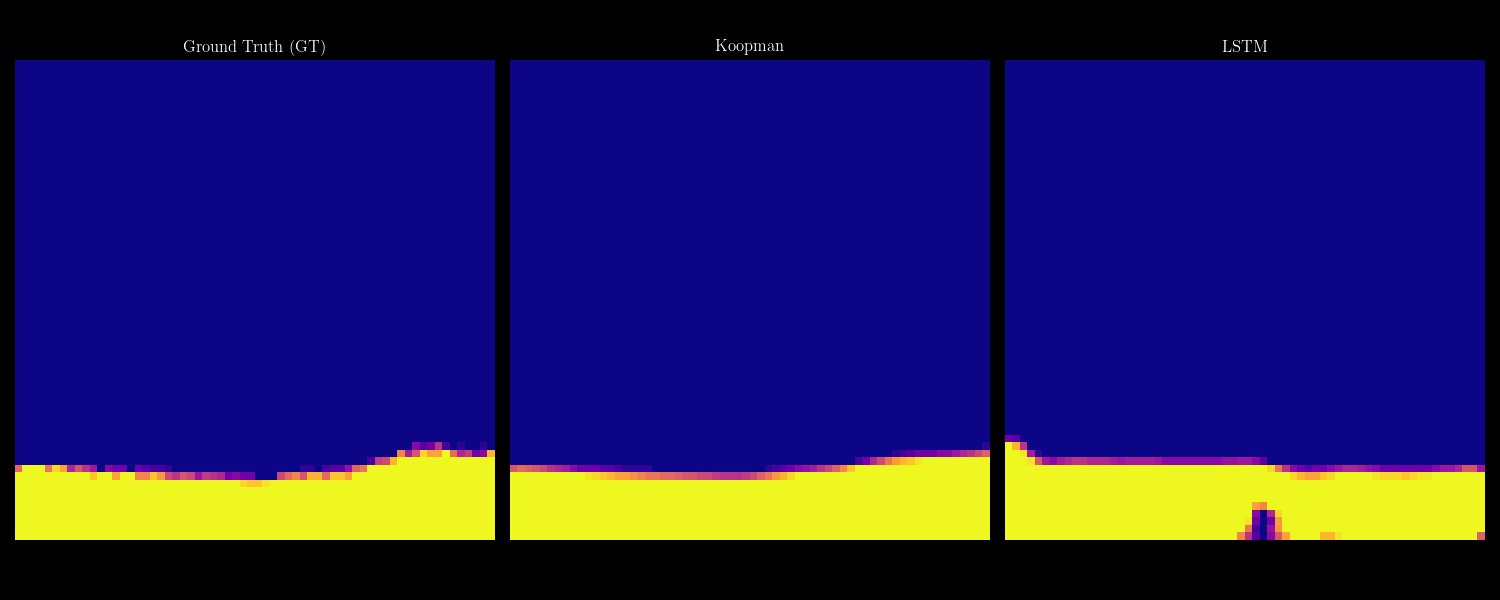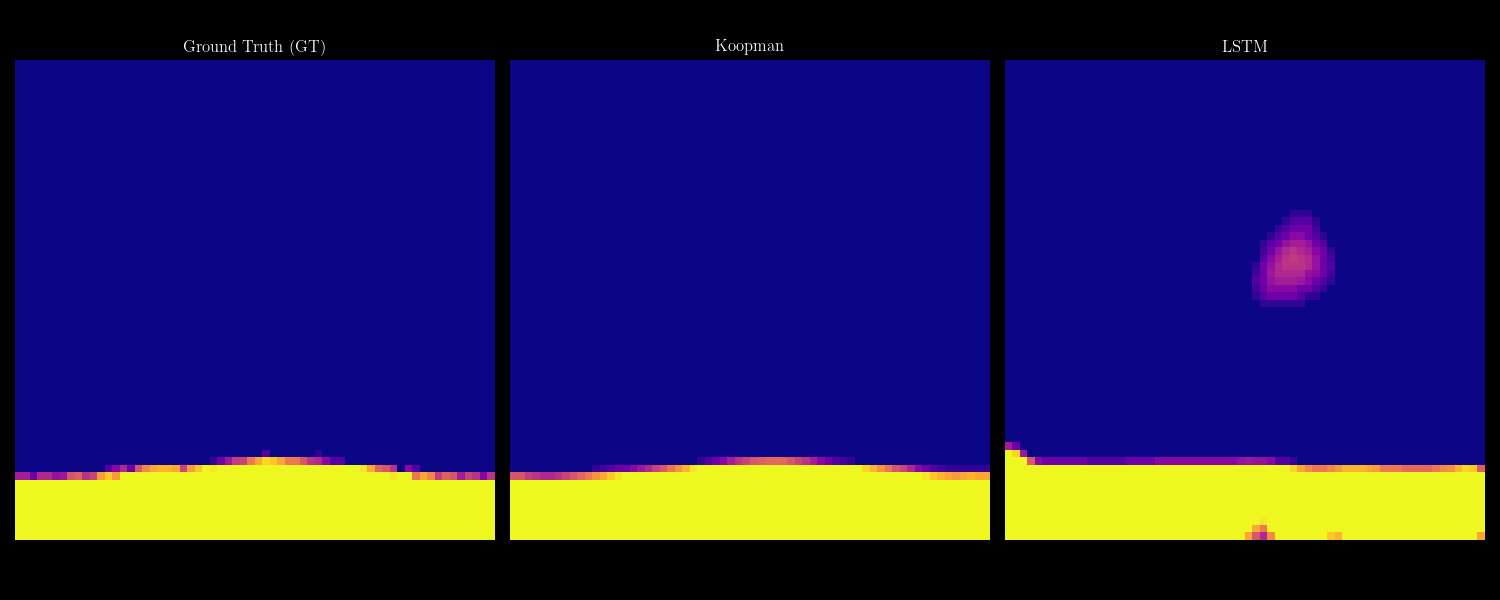
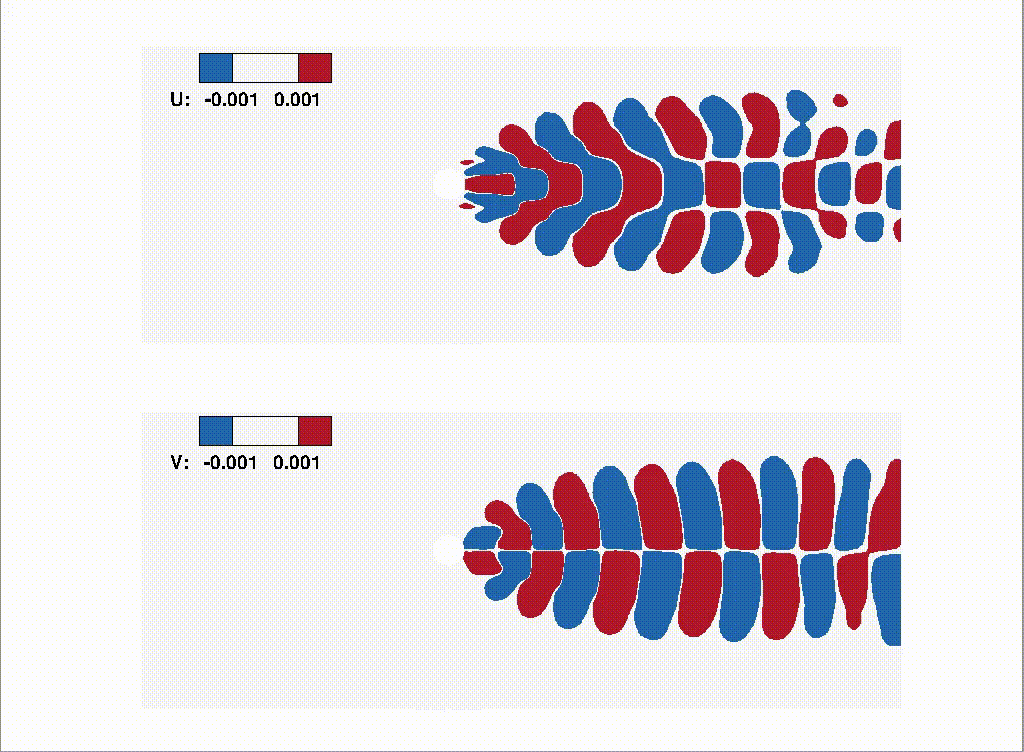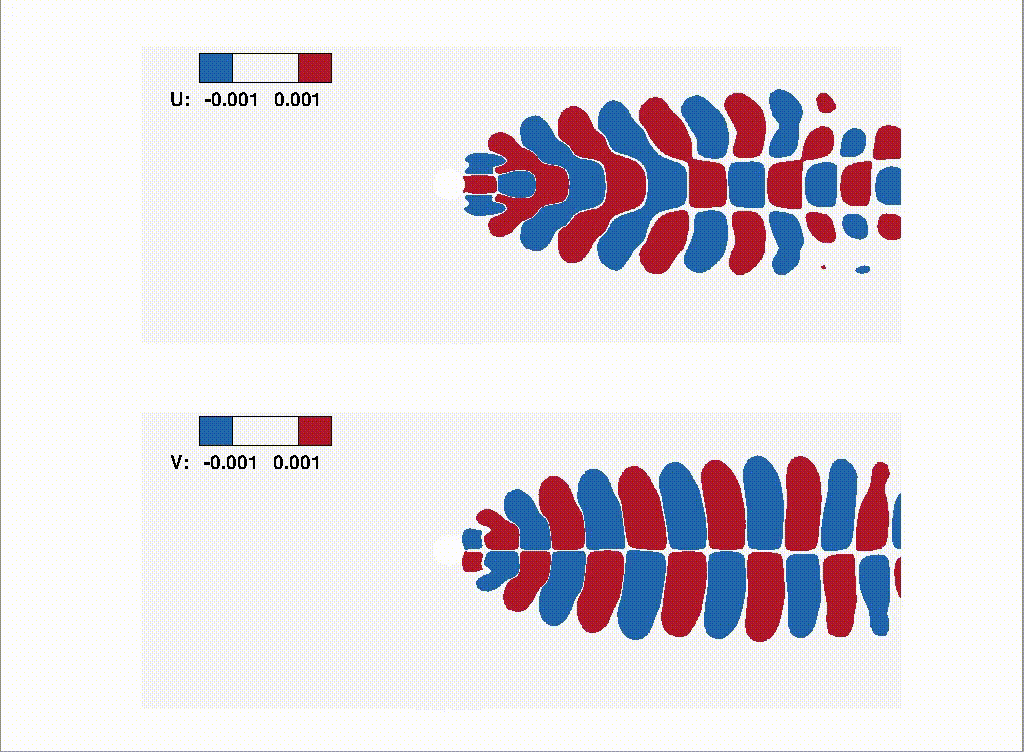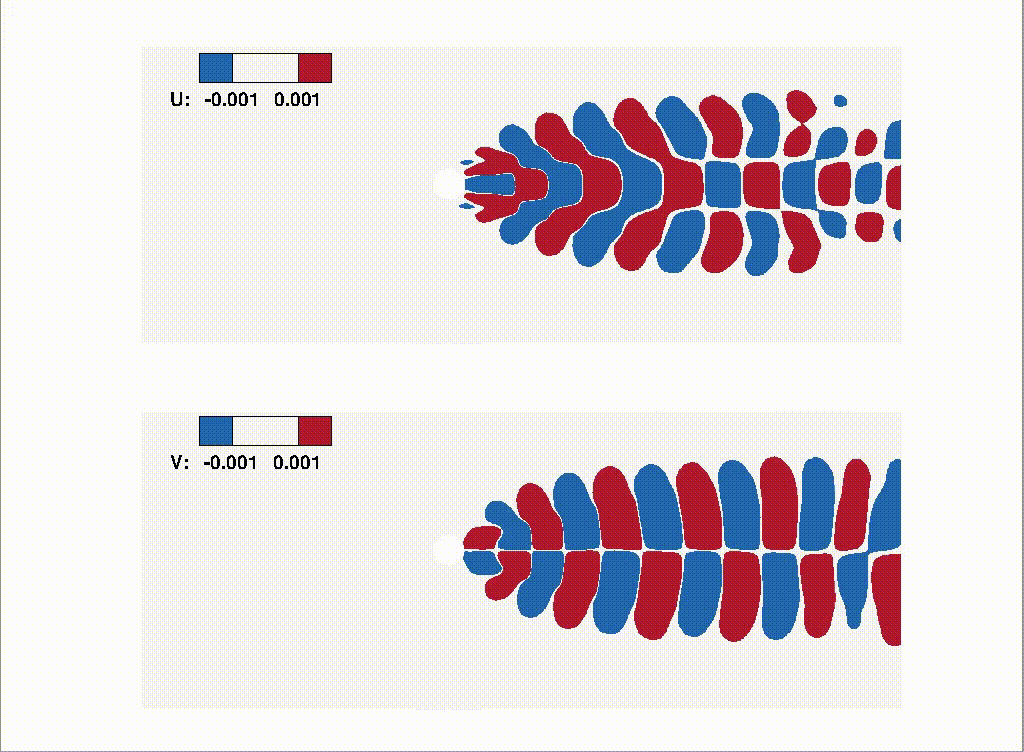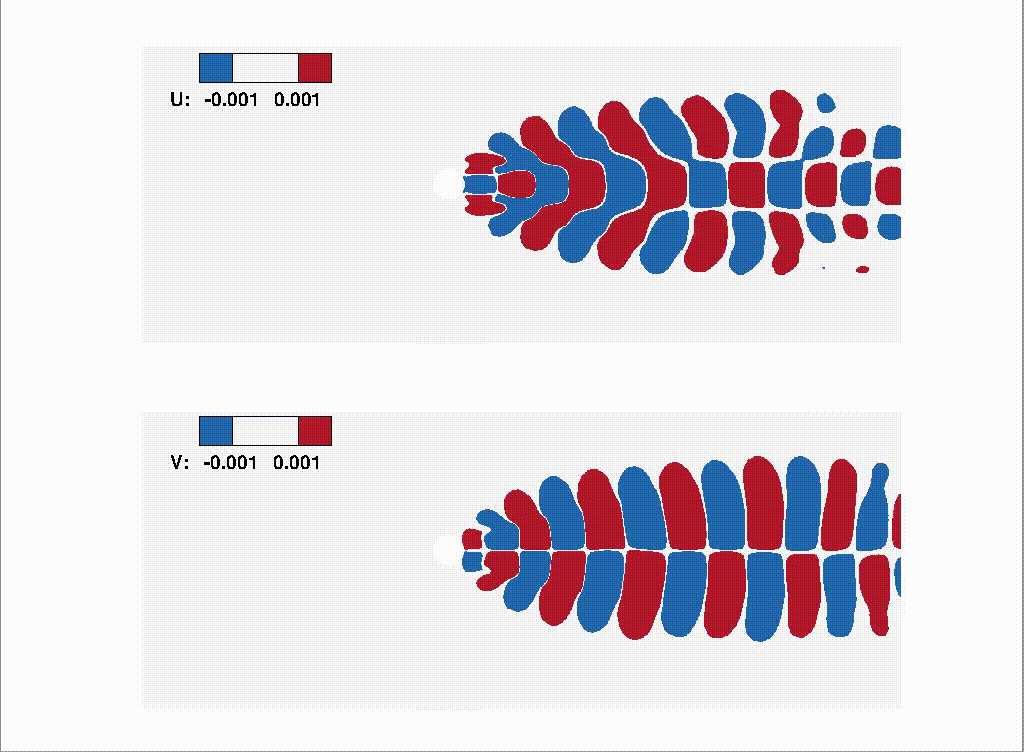
- 07/2026 Our collaboration with Shimin Di's group on self-evolving agents (FlowEvo) has been accepted to COLM 2026 [Paper] [Code]
- 06/2026 Ph.D. student Ling Yue published a paper as first author on domain-adaptive biomedical language models in Health Data Science [Paper]
- 06/2026 Ph.D. student Sai Bhargav Pochinapeddi received the Victor Peng '81 Summer Research Project Award
- 06/2026 Ph.D. students Ling Yue and Nithin Somasekharan are featured in the RPI Graduate Student Student Spotlight for their research in interdisciplinary AI and scientific machine learning
- 05/2026 Our collaboration with Min-Ling Zhang and Shimin Di's group on the automatic transformation of code repositories into MCP services (Code2MCP), earlier presented at NeurIPS 2025 Workshop SEA, has been published in KDD 2026 [Paper] [Code]
- 05/2026 Published a paper on neural-operator surrogate modeling for neutron transport in Nuclear Science and Engineering [Paper]
- 04/2026 Ph.D. student Ling Yue published a paper as first author on MCP-native hierarchical AI scientist ecosystems in Frontiers in Artificial Intelligence [Paper]
- 03/2026 Received NVIDIA Academic Grant Program Award
- 03/2026 Published a co-authored paper on accelerating PDE solver with equation-recast neural operators in Journal of Computational Physics [Paper]
- 02/2026 Ph.D. student Nithin Somasekharan published a paper as first author "CFDLLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics" in Journal of Data-centric Machine Learning Research [PDF] [Code]
- 01/2026 Yangyuan Li joined the CSML Lab as a new Ph.D. student. Welcome!
- 01/2026 Gave a talk on "Deep Koopman sensing" at Joint Mathematics Meetings in Washington, D.C. [Abstract]
- 01/2026 Published a paper on DeepONet for neutron transport modeling in Nuclear Science and Engineering [Paper]
- 12/2025 Ph.D. student Ling Yue published a paper as first author on multi-agent systems for CFD at NeurIPS 2025 Workshop ML4PS [Paper]
- 12/2025 Ph.D. student Ling Yue published a paper as first author on a fine-tuned LLM for OpenFOAM at NeurIPS 2025 Workshop ML4PS [Paper]
- 12/2025 Our collaboration with Sicheng He's group on the largest airfoil dataset has been published at NeurIPS 2025 [Paper] [Code]
- 09/2025 Ph.D. student Shahriar Akbar Sakib published a paper as first author on learning noise-robust stable Koopman operator for control with Hankel DMD in IEEE Transactions on Control Systems Technology [Paper]
- 08/2025 Ph.D. student Nithin Somasekharan published a paper as first author on nonlinear dimensionality reduction with convergence in Proceedings of The Royal Society A [Paper].
- 08/2025 Published a paper on parametric surrogate modeling for heat transfer with UQ in Progress in Nuclear Energy [Paper].
- 06/2025 Received Google Research Scholar Award [Link]
- 05/2025 Presented a work on "Toward Intelligent CFD Workflows in the Era of Large Language Models" at Algorithms For Multiphysics Models In The Post-Moore's Law Era in Los Alamos [Abstract]
- 05/2025 Presented a work on "Deep Koopman Sensing" at 1st International Symposium on AI and Fluid Mechanics [Abstract]
- 04/2025 Ph.D. student Nithin presented a work on "Deep Koopman Sensing" at 2nd ERCOFTAC Workshop on Machine Learning for Fluid Dynamics [Abstract]
- 04/2025 Ph.D. student Shahriar released a work on noise-robust Koopman operator with physics-informed observables [Paper].
- 11/2024 Ph.D. student Weichao presented a work on meshless surrogate models with stability guarantees at APS-DFD 2024 [Abstract].
- 11/2024 Co-advised Ph.D. student Isaac presented a work on data-driven surrogate models that accelerate fluid solver at APS-DFD 2024 [Abstract].
- 11/2024 Ph.D. student Nithin presented a work on convergence guaranteed autoencoder at APS-DFD 2024 [Abstract][Paper].
- 11/2024 Ph.D. student Weichao presented a work on meshless surrogate models with stability guarantees at MORE 2024 [Abstract].
- 11/2024 Ph.D. student Shahriar presented a work on learning Koopman operator from data at SIAM New York-New Jersey-Pennsylvania Section Conference [Abstract].
- 10/2024 Presented a work on meshless surrogate models with stability guarantees at AMS Fall Eastern Sectional Meeting [Abstract].
- 09/2024 Published a co-author paper on distributed deep compression of deep sea wavefield data on edge device on Journal of Geophysical Research: Machine Learning and Computation [Paper]
- 07/2024 Presented a work on meshless surrogate models with stability guarantees at WCCM 2024
- 07/2024 Presented a conference paper on learning parametric Koopman operator for hypersonic nonequilibrium flows at AIAA Aviation 2024. [Paper]
- 07/2024 Published a co-author paper on learning preconditioner for incomplete LU factorization at AIAA Aviation 2024. [Paper]
- 03/2024 Published a paper on the role of symmetry in lifting and reconstruction of Koopman operator with multiple invariant sets is published on Nonlinear Dynamics [Paper].
- 03/2024 Published a co-author paper on using physics-informed neural network (PINN) for solving plasma physics with different geometry on Physics of Plasmas [Paper][Editor Pick].
- 12/2023 Published a paper on The Journal of Open Source Software on a modular implementation of learning Koopman operator from data [Paper][Code]
- 11/2023 Ph.D. student Nithin presented a work on differentiable finite-element solver using Nvidia Warp at APS-DFD 2023 [Abstract]
- 01/2023 Published a paper meshless representation learning for PDE fields on Journal of Machine Learning Research [Paper]
- NVIDIA Academic Grant Program 2026
- Google Research Scholar Program 2025
- MICDE Fellowship 2018
- Chinese Outstanding Student Abroad Award (Ministry of Education of China, 500 globally) 2018
- Doctoral Fellowship 2016
- Rackham Summer Award 2015
- Richard and Eleanor Towner Prize for Outstanding Ph.D. Research (Department Nominee) 2019
- SIAM Student Travel Grant 2017
- Best Undergraduate Thesis in Fluid Mechanics (School of Aeronautical Engineering, Beihang University) 2013
- First Prize, College Mathematical Competition (2/1000, Beihang University) 2011
- Technical Committee: AIAA-FD, ICCS-TAMCS, IEEE Symposium
Series On Computational Intelligence 2024-present
- Panelist: NSF 2024
- Member: AIAA, AMS, APS, U.S. Association for Computational
Mechanics 2016-present
- Reviewer: Nature Machine Intelligence, Nature Computational Science, Nature Communications,
Science Advances, Communications Physics, Physical Review Letters,
Journal of Fluid Mechanics, Journal of Computational Physics, Geophysical Research Letters,
Proceedings of the Royal Society A, SIAM Journal on Scientific Computing,
SIAM Journal on Applied Dynamical Systems, Physica D: Nonlinear Phenomena,
Journal of Nonlinear Science, Nonlinear Dynamics, Chaos, Physical Review E,
Physical Review Fluids, Physics of Fluids, Journal of Fluids Engineering,
AIAA Journal, Lab on a Chip, Neural Networks, Machine Learning: Science and Technology,
Transactions on Pattern Analysis and Machine Intelligence, NeurIPS,
Journal of Machine Learning Research,
Computer Physics Communications, Communication in Computational Physics,
Computers and Fluids, International Journal for Numerical Methods in Engineering,
Journal of Sound and Vibration, Acta Mechanica Sinica, Theoretical and Applied Mechanics Letters,
Computational Science and Engineering, Chemical Engineering and Processing,
Journal of Computational Design and Engineering, Nuclear Materials and Energy,
IEEE Transactions on Automatic Control, IEEE Transactions on Signal Processing,
IEEE Transactions on Cybernetics, IEEE Transactions on Artificial Intelligence,
IEEE Transactions on Network Science and Engineering, IEEE Computational Intelligence Magazine,
IEEE Control Systems Letters, IEEE/CAA Journal of Automatica Sinica, IEEE Access,
Scientific Reports, PLOS One, Entropy, Applied Sciences, Mathematical Reviews,
Mathematical Problems in Engineering, AIAA conferences.
2016-present





